The model
trees are very similar to the CART principle and are often applied in the field
of economic research [9],[251]. Yet, each leaf contains
a local linear regression model instead of a single discrete value for the samples
passed to this leaf. Similar to CART an oversized tree is built in a first step.
Thereby the optimal criterion for the splitting of a node is the minimization
of the 2 standard deviations of the response variables of the samples assigned
to the 2 child nodes. In the second step, a pruning of the subtrees is performed.
Similar to the CART procedure, the nodes and leaves are pruned, which increase
the error of the calibration data less than a specified "size corrected"
value. For the calibration data of the refrigerant data set, a tree with 33
nodes and 35 leaves was built for R22 and a tree with 29 nodes and 32 leaves
was built for R134a. Both, the predictions of the validation data with relative
RMSE of 7.19% for R22 and 7.59 % for R134a and the predictions of the validation
data with relative RMSE for R22 of 10.29% and 11.20% for R134a were disappointing.
In principle, the model trees should be superior to the regression trees as
many local regression models are used instead of single discrete values. The
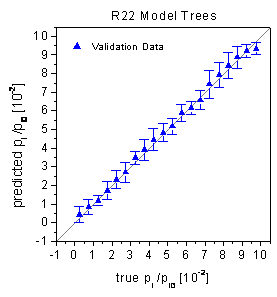
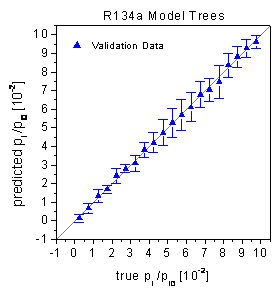
true-predicted plots in figure 40 show that the
predictions of the different concentration levels are rather inconsistent indicating
differences of the quality of the various local linear regression models. This
means that among the more than 30 local regression models per analyte not all
models are calibrated well. The data set might be too limited in size to calibrate
30 linear regression models successfully with single local models spoilt by
noise and outliers. Therefore, some local models are overfitted resulting in
the significant increase of the prediction error of the validation data. In
figure 40, no significant bias of the residuals
can be detected in agreement with the statistical tests. The locally weighted
regression (LWR) also uses the principle of many local linear regression models.
In contrast to the model trees, which separate the sample space by a tree into
local regions, the LWR generates local models at prediction time by weighting
samples in the neighborhood more. As the principle of local regression models
seems not to work for this highly correlated nonlinear refrigerant data set,
LWR and other methods based on local model are not investigated any further.
figure 40: True-predicted plots
of the model trees for the validation data.