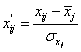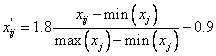Data
preprocessing can be used for systematically modifying the raw signals of the
device with the hope that the altered signals provide more useful input to the
calibration method. Unfortunately, no general guidelines exist to determine
the appropriate data preprocessing technique and thus the different preprocessing
techniques are controversially discussed in literature [7],[8].
In
this work, the input variables are preprocessed by autoscaling according to:
(2)
With as
response of the ith sample
at the jth variable, as the
mean of the jth
variable and as the standard deviation of the jth variable. Autoscaling
involves a mean-centering of the data and a division by the standard deviation
of all responses of a particular input variable resulting in a mean of zero and
a unit standard deviation of each variable. For some calibration methods
autoscaling can improve the calibration as autoscaling allows all variables to
influence equally the calibration especially if different variables show
different magnitudes of variation.
The
dependent variables were range-scaled between -0.9 to 0.9, which is essential
for calibration by neural networks with hyperbolic tangent activation functions,
according to:
(3)
For
the calculation of the prediction errors and the true-predicted plots, the
range-scaling was reversed.